Target encoding
The common approaches to encode categorical data are one-hot encoding and label encoding. Recently I encountered another method called “target encoding” which is more efficient. This technique is invented by Daniele Micci-Barreca (A preprocessing scheme for high-cardinality categorical attributes in classification and prediction problems).
The idea is using the relationship between the categorical feature x and the target
y in order to have a more meaningful numerical representation of x.
If x has N unique values xi then this relationship is defined as a function of the count of
xi (how many times that we observe x equals to xi)
and the mean y corresponding to each xi.
I did an experiment with the Kaggle Gun Violence dataset to figure out the effectiveness of target encoding method. The code of this experiment is available at https://github.com/tienduccao/blog_demo/blob/master/target_encoding/Demo.ipynb.
The target y in this dataset is n_killed which is the number of people killed from a gun violence indicent.
The categorical feature x is state where the indicent happened.
If we apply the
LabelEncoder on x, the encoded values would look like this
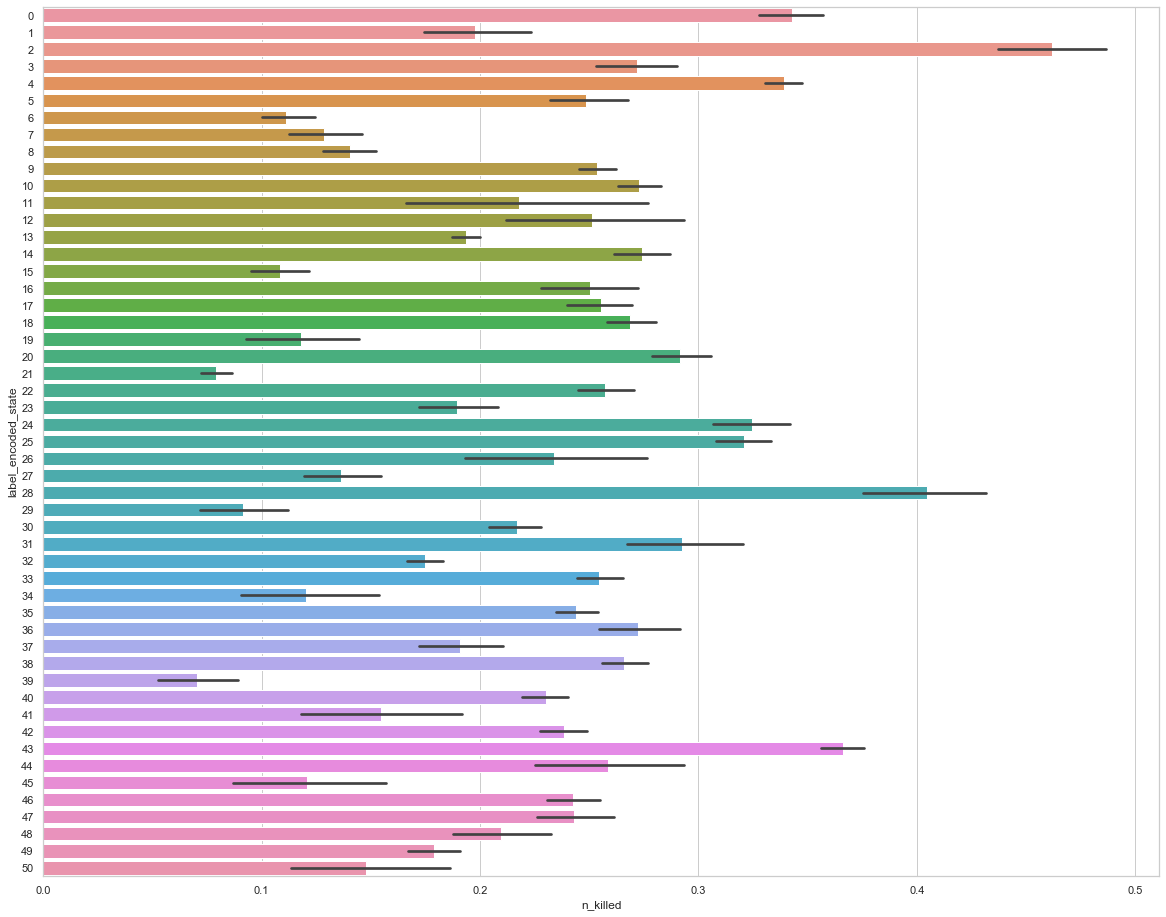 The following figure shows the encoded values of
The following figure shows the encoded values of x using
TargetEncoder
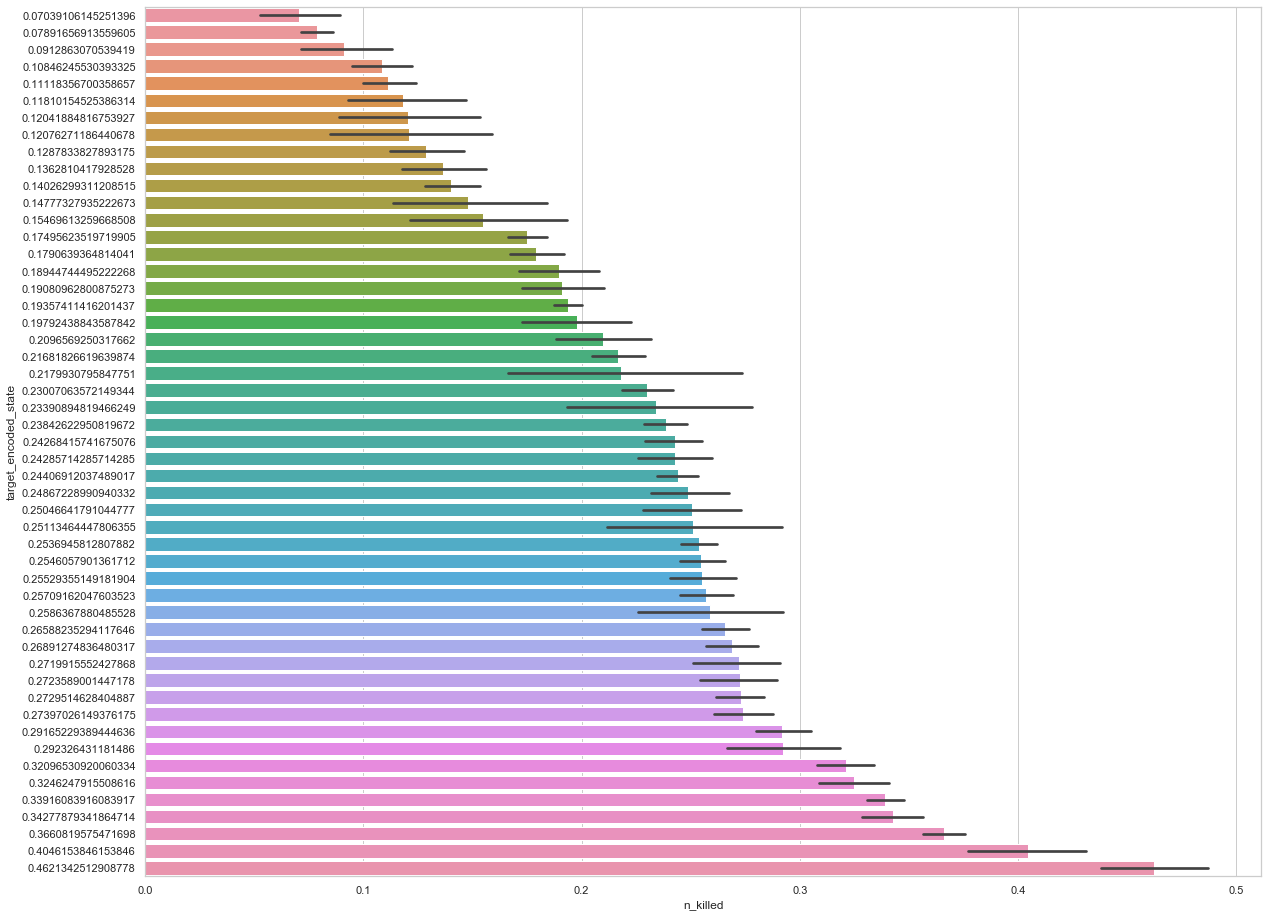 It is clear that the TargetEncoder’s encoded values reflect a trend of the target
It is clear that the TargetEncoder’s encoded values reflect a trend of the target n_killed.
To verify if TargetEncoder could help to improve model’s predictive power, I ran a RandomForestClassifier (5-folds stratified k-fold) on a set of categorical features (“state”, “city_or_county”, “gun_stolen”, “gun_type”, “participant_age_group”, “participant_gender”, “participant_relationship”, “participant_status”, “participant_type”) using
- (1) only LabelEncoder
- (2) TargetEncoder on features with high-cardinality (above 2K unique values) and LabelEncoder with the remaining features
The first approach achieves an average log-loss score of 0.02103 while the second one gets 0.01292.